
Hello world, I’m Tanmay and in this edition of my DevOps team blog, I would like to share some details on building a very highly available infrastructure backend. I work on designing reliable cloud services using various cloud providers for our clients. In the previous articles, I have mentioned about the cloud based storage systems and how to create serverless architecture with rest api.
Introduction
Everything that we use in day to days life has a presence on the internet one way or another, whether it be social media sites such as Facebook, Twitter, Quora etc. or online retailers such as Amazon, Flipkart.
All these websites connect us with one or another, who is using the same services. With an increased demand for reliable and performative infrastructures designed to serve critical systems, the terms scalability and high availability couldn’t be more popular than today’s date. While handling increased system load is a common concern, decreasing downtime and eliminating single points of failure are just as important. High availability is a quality of infrastructure design at scale that addresses these considerations.
So, what is this high availability?
Availability in computing terms is used to describe the period of time when a service is available for use, as well as time required by a system to respond to a request made by a user. High availability is a quality of a system or a device that assures a high operational performance for a given period of time. Availability is measured in % so when a system or a component gives 100% availability it means that this system never fails. For an instance, system that guarantees 99% of availability for a period of one year that means it could have a down time of 1% that is 3.65 days of downtime in one year.
Now imagine a service which is an e-commerce site and is very essential to its users for example Amazon. And now imagine it not operating for 3.65 days per year, this would mean there will be a loss of possibly millions of $’s due to loss of income over these 3.65 days to overcome this network solution architect ensures that there is a redundant system or component that can help in case of a fail-over in the main system or component of a main system.
So for an example let’s look at the below diagram which shows a highly available LAMP server (Linux Apache Mysql PHP) server implemented using Amazon Web Services. In case you are not familiar with AWS I am including a small description of each components and its use in the below diagram. The reason I am using AWS is because the most of the higher-level services, such as Amazon Simple Storage Service (S3), Amazon Simple Queue Service (SQS), have been built with fault tolerance and high availability in mind.
Having said that, the services that provide basic infrastructure, such as Amazon Elastic Compute Cloud (EC2) and Amazon Elastic Block Store (EBS), provide specific features, such as availability zones, elastic IP addresses, and snapshots, that a fault-tolerant and highly available system must take advantage of and use correctly. Just moving a system into the cloud doesn’t make it fault-tolerant or highly available.
AWS – Amazon Web Services.
VPC – Virtual Private Cloud, VPC is a tool by which you can design separate private clouds within an AWS Region.
Region – AWS Regions are geological locations from where AWS Data centres are operating, these locations can be used to design private or public resources using AWS services.
AZ – Availability zones (AZs) are distinct geographical locations that are engineered to be insulated from failures in other AZs. By placing Amazon EC2 instances in multiple AZs, an application can be protected from failure at a single location. It is important to run independent application stacks in more than one AZ, either in the same region or in another region, so that if one zone fails, the application in the other zone can continue to run. When you design such a system, you will need a good understanding of zone dependencies.
Route 53 – Amazon Route 53 (Route 53) is a scalable and highly available Domain Name System (DNS). It is part of AWS cloud computing platform. The name is a reference to TCP or UDP port 53, where DNS server requests are addressed.
ELB – Elastic Load Balancing is a load balancer which distributes incoming traffic across multiple resources so that one resource is not swamped with all the traffic. Load balancing is an effective way to increase the availability of a system. Instances that fail can be replaced seamlessly behind the load balancer while other instances continue to operate. Elastic Load Balancing can be used to balance across instances in multiple availability zones of a region.
EC2 – Elastic computing is virtual servers by which you can create resizable compute capacity in the cloud.
S3 – Amazon Simple Storage Service (Amazon S3) makes it simple and practical to collect, store, and analyze data regardless of its format and at a very massive scale.
RDS – Amazon Relational Database Service (Amazon RDS) is a web service that makes it easier to set up, operate, and scale a relational database in the cloud. It provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks.
This is a very brief description of some of the services that AWS provides. For more detailed information please refer the AWS Documentation.
Valuable data should never be stored only on instance storage without proper backups, replication, or the ability to re-create the data. Amazon Elastic Block Store (EBS) offers persistent off-instance storage volumes that are about an order of magnitude more durable than on-instance storage. EBS volumes are automatically replicated within a single availability zone. To increase durability further, point-in-time snapshots can be created to store data on volumes in Amazon S3, which is then replicated to multiple AZs. While EBS volumes are tied to a specific AZ, snapshots are tied to the region. Using a snapshot, you can create new EBS volumes in any of the AZs of the same region. This is an effective way to deal with disk failures or other host-level issues, as well as with problems affecting an AZ. Snapshots are incremental, so it is advisable to hold on to recent snapshots.
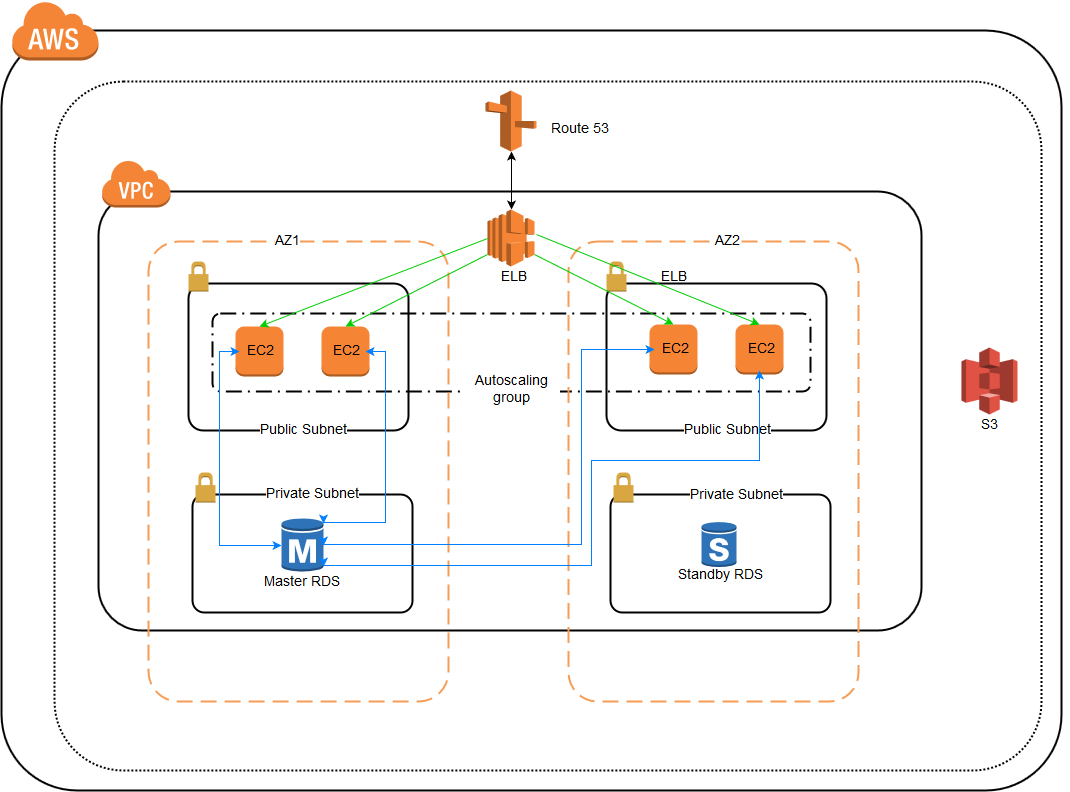
Getting back to HA, the above diagram is an example of how a highly available LAMP service can be created using the AWS cloud services.
Route 53 receives a request from the user, that gets forwarded to an ELB, the ELB then forwards this request to both AZ’s and thus to any EC2 servers running in those AZ’s, thus in case an entire AZ is down the other AZ still receives the request, for the EC2 server when receives the request it checks the connectivity with Master RDS, if it is not accessible then traffic is diverted to standby RDS.
For high availability, it is necessary that user gets same information whichever server or database is provided by the ELB. That is both EC2 server and database should be having same information to that of the other EC2 server and database. Otherwise it will not be useful if the user gets a different information every time the server is replaced by another by ELB.
This way the web server layer in this scenario is not a single point of failure because:
- redundant components for the same task are in place
- the mechanism on top of this layer (the load balancer) is able to detect failures in the components and adapt its behaviour for a timely recovery
But what happens if the load balancer goes offline?
With the described scenario, which is not uncommon in real life, the load balancing layer itself remains a single point of failure. Eliminating this remaining single point of failure, however, can be challenging; even though you can easily configure an additional load balancer to achieve redundancy, there isn’t an obvious point above the load balancers to implement failure detection and recovery. Redundancy alone cannot guarantee high availability. A mechanism must be in place for detecting failures and taking action when one of the components of your stack becomes unavailable. Failure detection and recovery for redundant systems can be implemented using a top-to-bottom approach: the layer on top becomes responsible for monitoring the layer immediately beneath it for failures. In our previous example scenario, the load balancer is the top layer. If one of the web servers (bottom layer) becomes unavailable, the load balancer will stop redirecting requests for that specific server.
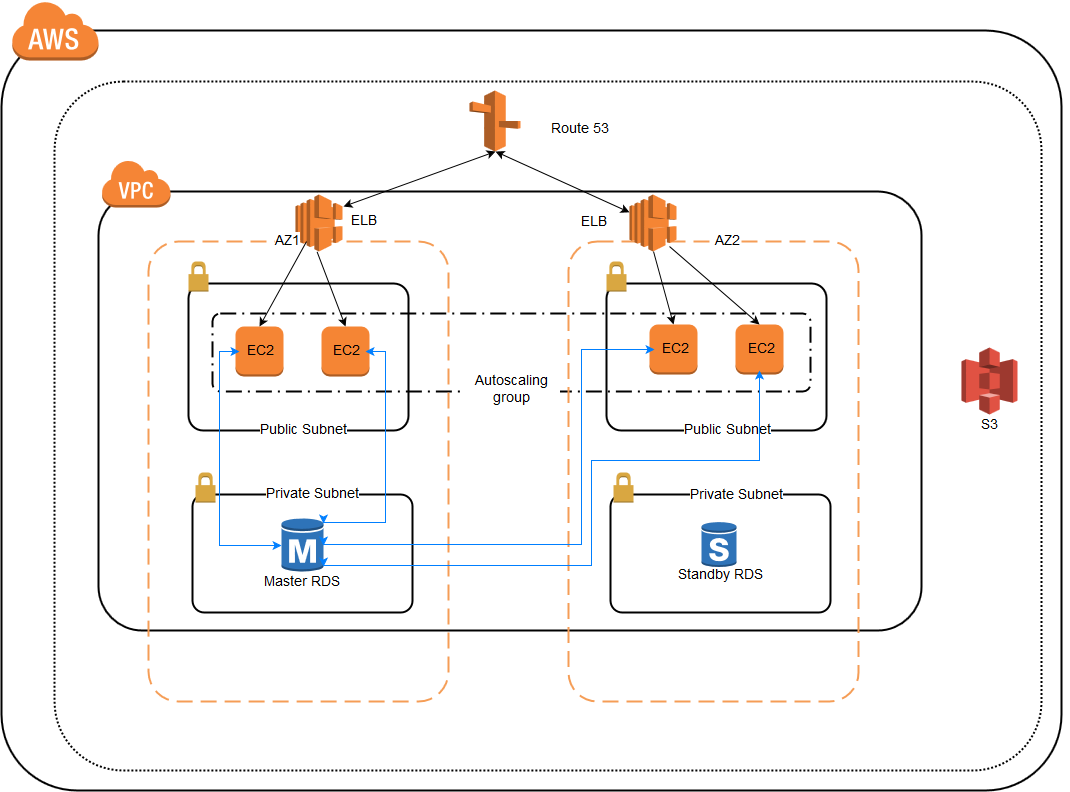
Above figure shows such an example we implemented for one of our client for their e-commerce website using AWS cloud platform.
With such a scenario, a distributed approach is necessary. Multiple redundant nodes must be connected together as a cluster where each node should be equally capable of failure detection and recovery. A more robust and reliable solution is to use systems that allow for flexible IP address remapping, such as floating IPs. On demand IP address remapping eliminates the propagation and caching issues inherent in DNS changes by providing a static IP address that can be easily remapped when needed. The domain name can remain associated with the same IP address, while the IP address itself is moved between servers.
What System Components Are Required for High Availability?
There are several components that must be carefully taken into consideration for implementing high availability in practice. Much more than a software implementation, high availability depends on factors such as:
- Environment: if all your servers are located in the same geographical area, an environmental condition such as an earthquake or flooding could take your whole system down. Having redundant servers in different datacentres and geographical areas will increase reliability.
- Hardware: highly available servers should be resilient to power outages and hardware failures, including hard disks and network interfaces.
- Software: the whole software stack, including the operating system and the application itself, must be prepared for handling unexpected failure that could potentially require a system restart, for instance.
- Data: data loss and inconsistency can be caused by several factors, and it’s not restricted to hard disk failures. Highly available systems must account for data safety in the event of a failure.
- Network: unplanned network outages represent another possible point of failure for highly available systems. It is important that a redundant network strategy is in place for possible failures.
Conclusion
High availability is an important subset of reliability engineering, focused towards assuring that a system or component has a high level of operational performance in a given period of time. At a first glance, its implementation might seem quite complex; however, it can bring tremendous benefits for systems that require increased reliability. Therefore, High Availability setups will give you an edge over your competitors. To know more about it and how to put it into practice, contact us at Ecomm India Cloud IT and we will be happy to chalk out a highly avaialable architecture that suits your application environment.